O dados desagrupados são aqueles que, obtidos a partir de um estudo, ainda não estão organizados por classes. Quando é um número gerenciável de dados, geralmente 20 ou menos, e há poucos dados diferentes, ele pode ser tratado como não agrupado e informações valiosas extraídas deles.
Os dados não agrupados são provenientes do inquérito ou do estudo efectuado para a sua obtenção e, por isso, carecem de processamento. Vejamos alguns exemplos:

-Resultados de um teste de QI em 20 alunos aleatórios de uma universidade. Os dados obtidos foram os seguintes:
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112.106
-Idade de 20 funcionários de uma certa cafeteria popular:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 21, 19, 22, 27, 29, 23, 20
-A média da nota final de 10 alunos em uma aula de matemática:
3,2; 3,1; 2,4; 4,0; 3,5; 3,0; 3,5; 3,8; 4,2; 4,9
Índice do artigo
Existem três propriedades importantes que caracterizam um conjunto de dados estatísticos, agrupados ou não, que são:
-Posição, que é a tendência dos dados de se agruparem em torno de certos valores.
-Dispersão, uma indicação de quão dispersos ou dispersos os dados estão em torno de um determinado valor.
-Forma, Refere-se à forma como os dados são distribuídos, o que é apreciado quando um gráfico dos mesmos é construído. Existem curvas muito simétricas e também enviesadas, seja para a esquerda ou para a direita de um determinado valor central.
Para cada uma dessas propriedades, há uma série de medidas que as descrevem. Depois de obtidos, eles nos fornecem uma visão geral do comportamento dos dados:
-As medidas de posição mais utilizadas são a média aritmética ou simplesmente média, a mediana e a moda.
-Faixa, variância e desvio padrão são freqüentemente usados na dispersão, mas não são as únicas medidas de dispersão..
-E para determinar a forma, a média e a mediana são comparadas por meio de viés, como você verá em breve.
-A média aritmética, também conhecido como média e denotado como X, é calculado da seguinte forma:
X = (x1 + xdois + x3 +… Xn) / n
Onde x1, xdois,… xn, são os dados en é o total deles. Em notação de soma, temos:
-Mediana é o valor que aparece no meio de uma sequência ordenada de dados, portanto, para obtê-lo, é necessário ordenar os dados antes de mais nada.
Se o número de observações for ímpar, não há problema em encontrar o ponto médio do conjunto, mas se tivermos um número par de dados, os dois dados centrais são pesquisados e calculados.
-Moda é o valor mais comum observado no conjunto de dados. Nem sempre existe, pois é possível que nenhum valor se repita com mais freqüência do que outro. Também poderia haver dois dados com igual frequência, caso em que falamos de uma distribuição bimodal.
Ao contrário das duas medidas anteriores, o modo pode ser usado com dados qualitativos.
Vamos ver como essas medidas de posição são calculadas com um exemplo:
Suponha que queremos determinar a média aritmética, mediana e moda no exemplo proposto no início: a idade de 20 funcionários de uma cafeteria:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 21, 19, 22, 27, 29, 23, 20
O metade é calculado simplesmente adicionando todos os valores e dividindo por n = 20, que é o número total de dados. Desta maneira:
X = (24 + 20 + 22 + 19 + 18 + 27+ 25 + 19 + 27 + 18 + 21 + 22 + 23 + 21+ 19 + 22 + 27+ 29 + 23+ 20) / 20 =
= 22,3 anos.
Para encontrar o mediana você precisa classificar o conjunto de dados primeiro:
18, 18, 19, 19, 19, 20, 20, 21, 21, 22, 22, 22, 23, 23, 24, 25, 27, 27, 27, 29
Como se trata de um número par de dados, os dois dados centrais, destacados em negrito, são calculados e calculados. Porque ambos têm 22 anos, a mediana é 22 anos.
finalmente, o moda É o dado que mais se repete ou aquele cuja frequência é maior, sendo este 22 anos.
O intervalo é simplesmente a diferença entre o maior e o menor dos dados e permite que você avalie rapidamente a variabilidade dos dados. Mas, à parte, existem outras medidas de dispersão que oferecem mais informações sobre a distribuição dos dados..
A variação é denotada como s e calculada pela expressão:
Portanto, para interpretar corretamente os resultados, o desvio padrão é definido como a raiz quadrada da variância, ou também o quase desvio padrão, que é a raiz quadrada da quase variância:
É a comparação entre a média X e a mediana Med:
-Se Med = significa X: os dados são simétricos.
-Quando X> Med: enviesado para a direita.
-E se X < Med: los datos sesgan hacia la izquierda.
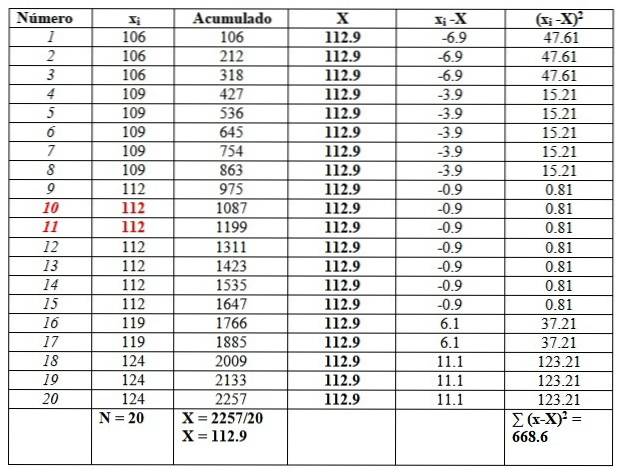
Encontre média, mediana, moda, intervalo, variância, desvio padrão e viés para os resultados de um teste de QI realizado em 20 alunos de uma universidade:
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112, 106
Vamos ordenar os dados, pois será necessário encontrar a mediana.
106, 106, 106, 109, 109, 109, 109, 109, 112, 112, 112, 112, 112, 112, 112, 119, 119, 119, 124, 124, 124
E vamos colocá-los em uma tabela como segue, para facilitar os cálculos. A segunda coluna intitulada "Acumulado" é a soma dos dados correspondentes mais os anteriores..
Esta coluna ajudará a encontrar facilmente a média, dividindo o último acumulado pelo número total de dados, conforme visto ao final da coluna "Acumulado":
X = 112,9
A mediana é a média dos dados centrais destacados em vermelho: o número 10 e o número 11. Como eles são iguais, a mediana é 112.
Por fim, a moda é o valor que mais se repete e é 112, com 7 repetições..
Em relação às medidas de dispersão, o intervalo é:
124-106 = 18.
A variância é obtida dividindo o resultado final na coluna da direita por n:
s = 668,6 / 20 = 33,42
Neste caso, o desvio padrão é a raiz quadrada da variância: √33,42 = 5,8.
Por outro lado, os valores da quase-variância e do quase desvio padrão são:
sc= 668,6 / 19 = 35,2
Desvio quase padrão = √35,2 = 5,9
Finalmente, o viés é ligeiramente para a direita, uma vez que a média 112,9 é maior do que a mediana 112.



Ainda sem comentários