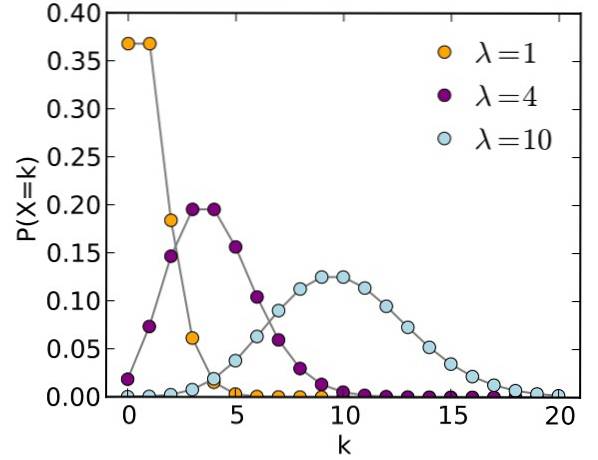
O Distribuição de veneno é uma distribuição de probabilidade discreta, através da qual é possível saber a probabilidade de que, dentro de um grande tamanho de amostra e durante um determinado intervalo, ocorra um evento cuja probabilidade é pequena..
Muitas vezes, a distribuição de Poisson pode ser usada no lugar da distribuição binomial, desde que as seguintes condições sejam atendidas: grande amostra e pequena probabilidade.
Siméon-Denis Poisson (1781-1840) criou esta distribuição que leva seu nome, muito útil quando se trata de eventos imprevisíveis. Poisson publicou seus resultados em 1837, um trabalho de pesquisa sobre a probabilidade de ocorrência de sentenças criminais errôneas.
Posteriormente, outros pesquisadores adaptaram a distribuição em outras áreas, por exemplo, o número de estrelas que poderiam ser encontradas em um determinado volume do espaço, ou a probabilidade de um soldado morrer com o coice de um cavalo.
Índice do artigo
A forma matemática da distribuição de Poisson é a seguinte:

- μ (também às vezes denotado como λ) é a média ou parâmetro da distribuição
- Número de Euler: e = 2,71828
- A probabilidade de obter y = k é P
- k é o número de sucessos 0, 1,2,3 ...
- n é o número de testes ou eventos (o tamanho da amostra)
Variáveis aleatórias discretas, como seu nome indica, dependem do acaso e só assumem valores discretos: 0, 1, 2, 3, 4 ..., k.
A média da distribuição é dada por:
A variância σ, que mede a dispersão dos dados, é outro parâmetro importante. Para a distribuição de Poisson é:
σ = μ
Poisson determinou que quando n → ∞, ep → 0, a média μ -também chamada valor esperado- tende a uma constante:
µ → constante
Importante: p é a probabilidade de ocorrência do evento levando em consideração a população total, enquanto P (y) é a previsão de Poisson na amostra.
A distribuição de Poisson possui as seguintes propriedades:
-O tamanho da amostra é grande: n → ∞.
-Os eventos ou eventos considerados são independentes uns dos outros e ocorrem aleatoriamente.
-Probabilidade P aquele determinado evento Y ocorre durante um período específico de tempo é muito pequeno: P → 0.
-A probabilidade de que mais de um evento ocorra no intervalo de tempo é 0.
-O valor médio se aproxima de uma constante dada por: μ = n.p (n é o tamanho da amostra)
-Como a dispersão σ é igual a μ, ao adotar valores maiores, a variabilidade também se torna maior.
-Os eventos devem ser distribuídos uniformemente no intervalo de tempo usado.
-O conjunto de valores de eventos possíveis Y é: 0,1,2,3,4 ... .
-A soma de eu variáveis que seguem uma distribuição de Poisson, também é outra variável de Poisson. Seu valor médio é a soma dos valores médios dessas variáveis.
A distribuição de Poisson difere da distribuição binomial nas seguintes maneiras importantes:
-A distribuição binomial é afetada tanto pelo tamanho da amostra n quanto pela probabilidade P, mas a distribuição de Poisson só é afetada pela média µ.
-Em uma distribuição binomial, os valores possíveis da variável aleatória Y são 0,1,2,…, N, por outro lado na distribuição de Poisson não há limite superior para esses valores.
Poisson inicialmente aplicou sua famosa distribuição a casos legais, mas em um nível industrial, um de seus primeiros usos foi na fabricação de cerveja. Neste processo, as culturas de levedura são usadas para fermentação.
A levedura consiste em células vivas, cuja população é variável ao longo do tempo. Na fabricação de cerveja é necessário adicionar a quantidade necessária, pois é necessário saber a quantidade de células que existem por unidade de volume..
Durante a Segunda Guerra Mundial, a distribuição de Poisson foi usada para descobrir se os alemães estavam realmente mirando em Londres de Calais, ou apenas atirando ao acaso. Isso foi importante para os Aliados determinarem o quão boa a tecnologia estava disponível para os nazistas..
As aplicações da distribuição de Poisson sempre se referem a contagens no tempo ou contagens no espaço. E como a probabilidade de ocorrência é pequena, também é conhecida como a "lei dos eventos raros".
Aqui está uma lista de eventos que se enquadram em uma dessas categorias:
-Registro das partículas em um decaimento radioativo, que como o crescimento de células de levedura, é uma função exponencial.
-Número de visitas a um determinado site.
-Chegada de pessoas na fila para pagar ou ser atendido (teoria da fila).
-Número de carros que passam por determinado ponto em uma estrada, durante um determinado intervalo de tempo.
-Mutações em uma determinada fita de DNA após receber exposição à radiação.
-Número de meteoritos com diâmetro superior a 1 m caídos em um ano.
-Defeitos por metro quadrado de tecido.
-Número de células sanguíneas em 1 centímetro cúbico.
-Chamadas por minuto para uma central telefônica.
-Pedaços de chocolate presentes em 1 kg de massa de bolo.
-Número de árvores infectadas por um certo parasita em 1 hectare de floresta.
Observe que essas variáveis aleatórias representam o número de vezes que um evento ocorre durante um período fixo de tempo (ligações por minuto para a central telefônica), ou uma determinada região do espaço (defeitos de um tecido por metro quadrado).
Esses eventos, como já foi estabelecido, independem do tempo decorrido desde a última ocorrência..
A distribuição de Poisson é uma boa aproximação da distribuição binomial, desde que:
-O tamanho da amostra é grande: n ≥ 100
-Probabilidade p é pouco: p ≤ 0,1
- µ está na ordem de: np ≤ 10
Nesses casos, a distribuição de Poisson é uma excelente ferramenta, uma vez que a distribuição binomial pode ser difícil de aplicar nesses casos..
Um estudo sismológico determinou que durante os últimos 100 anos, ocorreram 93 grandes terremotos ao redor do mundo, pelo menos 6,0 na escala Richter -logarítmica-. Suponha que a distribuição de Poisson seja um modelo adequado neste caso. Achar:
a) A ocorrência média de grandes terremotos por ano.
b) sim P (y) é a probabilidade de ocorrência Y terremotos durante um ano selecionado aleatoriamente, encontre as seguintes probabilidades:
P(0), P(1), P (dois), P (3), P (4), P (5), P (6) e P (7).
c) Os verdadeiros resultados do estudo são os seguintes:
- 47 anos (0 terremotos)
- 31 anos (1 terremotos)
- 13 anos (2 terremotos)
- 5 anos (3 terremotos)
- 2 anos (4 terremotos)
- 0 anos (5 terremotos)
- 1 ano (6 terremotos)
- 1 ano (7 terremotos)
Como esses resultados se comparam aos obtidos na parte b? A distribuição de Poisson é uma boa escolha para modelar esses eventos?
a) Terremotos são eventos cuja probabilidade p é pequeno e estamos considerando um período restrito de um ano. O número médio de terremotos é:
μ = 93/100 terremotos / ano = 0,93 terremotos por ano.
b) Para calcular as probabilidades solicitadas, os valores são substituídos na fórmula dada no início:
y = 2
μ = 0,93
e = 2,71828

É muito menos que P (2).
Os resultados estão listados abaixo:
P (0) = 0,395, P (1) = 0,367, P (2) = 0,171, P (3) = 0,0529, P (4) = 0,0123, P (5) = 0,00229, P (6) = 0,000355, P (7) = 0,0000471.
Por exemplo, podemos dizer que existe uma probabilidade de 39,5% de que nenhum grande terremoto ocorrerá em um determinado ano. Ou que há 5,29% de 3 grandes terremotos ocorrendo naquele ano.
c) As frequências são analisadas, multiplicando por n = 100 anos:
39,5; 36,7; 17,1; 5,29; 1,23; 0,229; 0,0355 e 0,00471.
Por exemplo:
- Uma frequência de 39,5 indica que, em 39,5 de 100 anos, 0 grandes terremotos ocorrem, podemos dizer que é bem próximo do resultado real de 47 anos sem nenhum grande terremoto..
Vamos comparar outro resultado de Poisson com os resultados reais:
- O valor obtido de 36,7 significa que em um período de 37 anos ocorre 1 grande terremoto. O resultado real é que em 31 anos ocorreu um grande terremoto, uma boa combinação com o modelo.
- São esperados 17,1 anos com 2 grandes terremotos e sabe-se que em 13 anos, que é um valor próximo, ocorreram de fato 2 grandes terremotos.
Portanto, o modelo de Poisson é aceitável para este caso.
Uma empresa estima que o número de componentes que falham antes de chegar a 100 horas de operação segue uma distribuição de Poisson. Se o número médio de falhas for 8 nesse tempo, encontre as seguintes probabilidades:
a) Que um componente falha em 25 horas.
b) Falha de menos de dois componentes, em 50 horas.
c) Falha de pelo menos três componentes em 125 horas.
a) Sabe-se que a média de falhas em 100 horas é de 8, portanto em 25 horas é esperado um quarto de falhas, ou seja, 2 falhas. Este será o parâmetro µ.
A probabilidade de que 1 componente falhe é solicitada, a variável aleatória é "componentes que falham antes de 25 horas" e seu valor é y = 1. Substituindo na função de probabilidade:
No entanto, a questão é a probabilidade de eles falharem menos de dois componentes em 50 horas, não que exatamente 2 componentes falhem em 50 horas, portanto, devemos adicionar as probabilidades de:
-Nenhum falha
-Falha apenas 1
P (falha em menos de 2 componentes) = P (0) + P (1)
P (falha em menos de 2 componentes) = 0,0183 + 0,0732 = 0.0915
c) Que eles falham pelo menos 3 componentes em 125 horas, significa que 3, 4, 5 ou mais podem falhar nesse tempo.
A probabilidade de que ocorra ao menos um de vários eventos é igual a 1, menos a probabilidade de nenhum dos eventos ocorrer.
-O evento desejado é que 3 ou mais componentes falhem em 125 horas
-Se o evento não ocorrer, significa que menos de 3 componentes falham, cuja probabilidade é: P (0) + P (1) + P (2)
O parâmetro μ da distribuição neste caso é:
μ = 8 + 2 = 10 falhas em 125 horas.
P (3 ou mais componentes falham) = 1- P (0) - P (1) - P (2) =


Ainda sem comentários