O Distribuição F o A distribuição Fisher-Snedecor é aquela usada para comparar as variâncias de duas populações diferentes ou independentes, cada uma das quais segue uma distribuição normal.
A distribuição que segue a variância de um conjunto de amostras de uma única população normal é a distribuição qui-quadrado (Χdois) de grau n-1, se cada uma das amostras no conjunto tiver n elementos.
Para comparar as variâncias de duas populações diferentes, é necessário definir um estatístico, isto é, uma variável aleatória auxiliar que nos permite discernir se ambas as populações têm ou não a mesma variância.
A referida variável auxiliar pode ser diretamente o quociente das variâncias amostrais de cada população, caso em que, se o referido quociente for próximo da unidade, há evidências de que ambas as populações possuem variâncias semelhantes..
Índice do artigo
A variável aleatória F ou estatística F proposta por Ronald Fisher (1890 - 1962) é a mais frequentemente usada para comparar as variâncias de duas populações e é definida da seguinte forma:
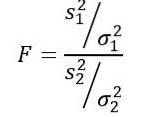
Sendo sdois a variância da amostra e σdois a variância da população. Para distinguir cada um dos dois grupos populacionais, os índices 1 e 2 são usados respectivamente..
Sabe-se que a distribuição qui-quadrado com (n-1) graus de liberdade é aquela que segue a variável auxiliar (ou estatística) definida a seguir:
Xdois = (n-1) sdois / σdois.
Portanto, a estatística F segue uma distribuição teórica dada pela seguinte fórmula:
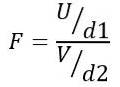
Sendo OU a distribuição do qui-quadrado com d1 = n1 - 1 graus de liberdade para a população 1 e V a distribuição do qui-quadrado com d2 = n2 - 1 graus de liberdade para a população 2.
O quociente definido desta forma é uma nova distribuição de probabilidade, conhecida como Distribuição F com d1 graus de liberdade no numerador e d2 graus de liberdade no denominador.
A média da distribuição F é calculada da seguinte forma:
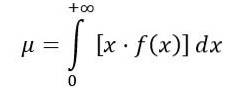
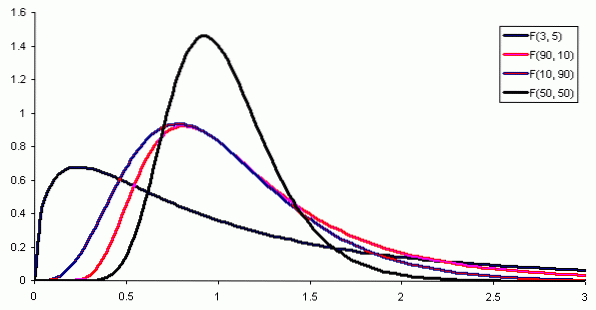
Onde f (x) é a densidade de probabilidade da distribuição F, que é mostrada na figura 1 para várias combinações de parâmetros ou graus de liberdade.
Podemos escrever a densidade de probabilidade f (x) como uma função da função Γ (função gama):
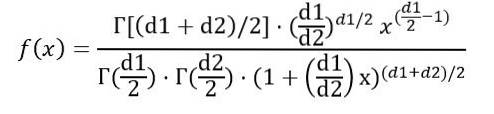
Uma vez realizada a integral indicada acima, conclui-se que a média da distribuição F com graus de liberdade (d1, d2) é:
μ = d2 / (d2 - 2) com d2> 2
Onde se nota que, curiosamente, a média independe dos graus de liberdade d1 do numerador.
Por outro lado, o modo depende de d1 e d2 e é dado por:
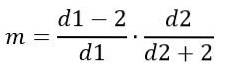
Para d1> 2.
A variância σdois da distribuição F é calculado a partir do integral:
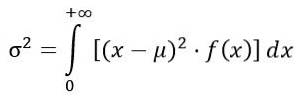
Obtendo:
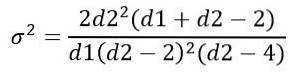
Como outras distribuições de probabilidade contínua que envolvem funções complicadas, o tratamento da distribuição F é feito usando tabelas ou software..
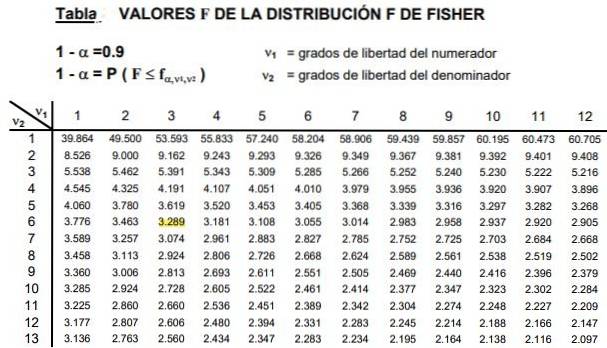
As tabelas envolvem os dois parâmetros ou graus de liberdade da distribuição F, a coluna indica o grau de liberdade do numerador e a linha o grau de liberdade do denominador.
A Figura 2 mostra uma seção da tabela da distribuição F para o caso de um nível de significância de 10%, ou seja, α = 0,1. O valor de F é destacado quando d1 = 3 e d2 = 6 com nível de confiança 1- α = 0,9 que é 90%.
Quanto ao software que trata a distribuição F existe uma grande variedade, desde planilhas como Excel para pacotes especializados como minitab, SPSS Y R para citar alguns dos mais conhecidos.
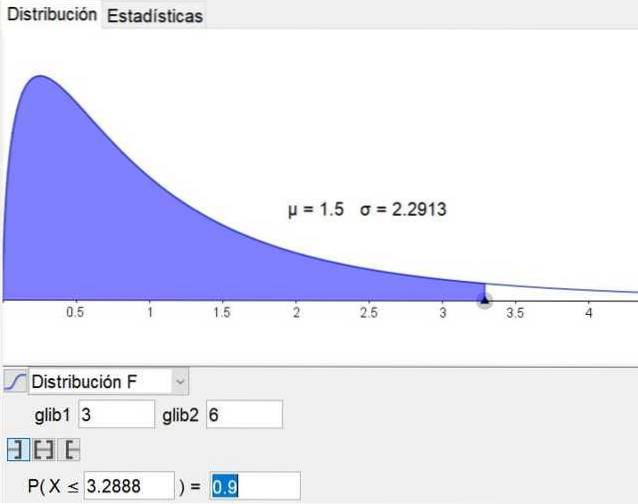
Vale ressaltar que o software de geometria e matemática geogebra possui uma ferramenta estatística que inclui as principais distribuições, incluindo a distribuição F. A Figura 3 mostra a distribuição F para o caso d1 = 3 e d2 = 6 com nível de confiança de 90%.
Considere duas amostras de populações que têm a mesma variância populacional. Se a amostra 1 tem tamanho n1 = 5 e a amostra 2 tem tamanho n2 = 10, determine a probabilidade teórica de que o quociente de suas respectivas variâncias seja menor ou igual a 2.
Deve ser lembrado que a estatística F é definida como:
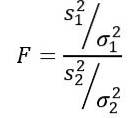
Mas somos informados de que as variâncias da população são iguais, portanto, para este exercício, aplica-se o seguinte:
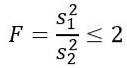
Como queremos saber a probabilidade teórica de que esse quociente de variâncias da amostra seja menor ou igual a 2, precisamos conhecer a área sob a distribuição F entre 0 e 2, que pode ser obtida por meio de tabelas ou software. Para isso, deve-se levar em consideração que a distribuição F exigida tem d1 = n1 - 1 = 5 - 1 = 4 e d2 = n2 - 1 = 10 - 1 = 9, ou seja, a distribuição F com graus de liberdade ( 4, 9).
Usando a ferramenta estatística de geogebra Determinou-se que esta área é 0,82, portanto, conclui-se que a probabilidade do quociente das variâncias da amostra ser menor ou igual a 2 é de 82%..
Existem dois processos de fabricação para chapas finas. A variabilidade da espessura deve ser a mais baixa possível. 21 amostras são retiradas de cada processo. A amostra do processo A tem um desvio padrão de 1,96 mícrons, enquanto a amostra do processo B tem um desvio padrão de 2,13 mícrons. Qual dos processos tem a menor variabilidade? Use um nível de rejeição de 5%.
Os dados são os seguintes: Sb = 2,13 com nb = 21; Sa = 1,96 com na = 21. Isso significa que temos que trabalhar com uma distribuição F de (20, 20) graus de liberdade.
A hipótese nula implica que a variância da população de ambos os processos é idêntica, ou seja, σa ^ 2 / σb ^ 2 = 1. A hipótese alternativa implicaria diferentes variâncias da população.
Então, sob a suposição de variâncias populacionais idênticas, a estatística F calculada é definida como: Fc = (Sb / Sa) ^ 2.
Uma vez que o nível de rejeição foi considerado α = 0,05, então α / 2 = 0,025
A distribuição F (0,025, 20,20) = 0,406, enquanto F (0,975, 20,20) = 2,46.
Portanto, a hipótese nula será verdadeira se o F calculado corresponder a: 0,406≤Fc≤2,46. Caso contrário, a hipótese nula é rejeitada.
Como Fc = (2,13 / 1,96) ^ 2 = 1,18 conclui-se que a estatística Fc está na faixa de aceitação da hipótese nula com uma certeza de 95%. Em outras palavras, com 95% de certeza, ambos os processos de manufatura têm a mesma variância populacional..



Ainda sem comentários