O erro de amostragem ou erro de amostra Em estatística, é a diferença entre o valor médio de uma amostra e o valor médio da população total. Para ilustrar a ideia, vamos imaginar que a população total de uma cidade seja de um milhão de pessoas, da qual se deseja o tamanho médio do calçado, para o qual é retirada uma amostra aleatória de mil pessoas.
O tamanho médio que emerge da amostra não coincidirá necessariamente com o da população total, embora se a amostra não for enviesada o valor deve ser próximo. Essa diferença entre o valor médio da amostra e o da população total é o erro amostral.
Em geral, o valor médio da população total é desconhecido, mas existem técnicas para reduzir este erro e fórmulas para estimar o margem de erro de amostragem que será exposto neste artigo.
Índice do artigo
Digamos que você queira saber o valor médio de uma certa característica mensurável x em uma população de tamanho N, mas como N é um número grande, não é viável fazer o estudo sobre a população total, então passamos a fazer um amostra aleatória de tamanho n<
O valor médio da amostra é denotado por
Suponha que eles tomem m amostras da população total N, todos do mesmo tamanho n com valores médios
Esses valores médios não serão idênticos entre si e serão todos em torno do valor médio da população µ. O margem de erro de amostragem E indica a separação esperada dos valores médios
O margem de erro padrão ε amostra de tamanho n isso é:
ε = σ / √n
Onde σ é o desvio padrão (a raiz quadrada da variação), que é calculada usando a seguinte fórmula:
σ = √ [(x -
O significado de margem de erro padrão ε é o seguinte:
O valor médio
Na seção anterior, a fórmula foi dada para encontrar o margem de erro padrão de uma amostra de tamanho n, onde a palavra padrão indica que é uma margem de erro com 68% de confiança.
Isso indica que se muitas amostras do mesmo tamanho foram tomadas n, 68% deles darão valores médios
Existe uma regra simples, chamada de regra 68-95-99,7 o que nos permite encontrar a margem de erro de amostragem E para níveis de confiança de 68%, 95% Y 99,7% facilmente, uma vez que esta margem é 1⋅ε, 2⋅ε e 3⋅ε respectivamente.
Se ele nível de confiança γ não é nenhuma das opções acima, então o erro de amostragem é o desvio padrão σ multiplicado pelo fator Zγ, que é obtido através do seguinte procedimento:
1.- Primeiro o nível de significância α que é calculado a partir de nível de confiança γ usando a seguinte relação: α = 1 - γ
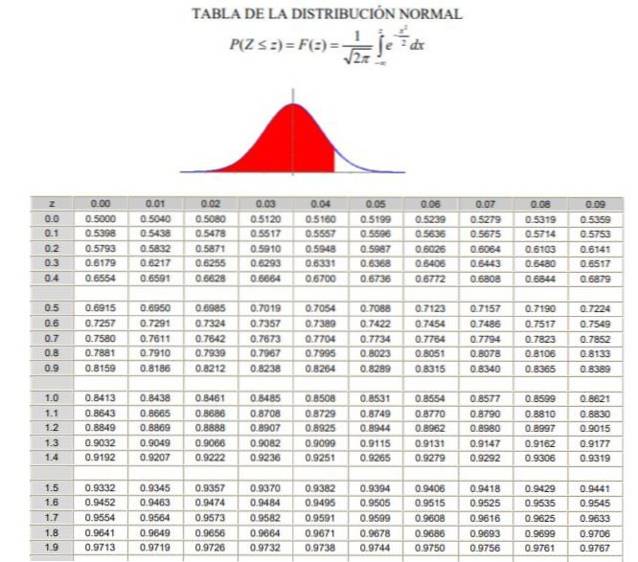
2.- Depois deve calcular o valor 1 - α / 2 = (1 + γ) / 2, que corresponde à frequência normal acumulada entre -∞ e Zγ, em uma distribuição gaussiana normal ou padronizada F (z), cuja definição pode ser vista na figura 2.
3.- A equação está resolvida F (Zγ) = 1 - α / 2 por meio das tabelas da distribuição normal (cumulativa) F, ou por meio de um aplicativo de computador que tem a função gaussiana padronizada inversa F-1.
No último caso, temos:
Zγ = G-1(1 - α / 2).
4.- Finalmente, esta fórmula é aplicada para o erro de amostragem com um nível de confiabilidade γ:
E = Zγ⋅(σ / √n)
Calcule o margem de erro padrão no peso médio de uma amostra de 100 recém-nascidos. O cálculo do peso médio foi
O margem de erro padrão isso é ε = σ / √n = (1.500 kg) / √100 = 0,15 kg. O que significa que com esses dados pode-se inferir que o peso de 68% dos recém-nascidos está entre 2.950 kg e 3,25 kg.
Determinar a margem de erro de amostragem E e a faixa de peso de 100 recém-nascidos com um nível de confiança de 95% se o peso médio for 3.100 kg com desvio padrão σ = 1.500 kg.
Se o regra 68; 95; 99,7 → 1⋅ε; 2⋅ε; 3⋅ε, se tem:
E = 2⋅ε = 2⋅0,15 kg = 0,30 kg
Ou seja, 95% dos recém-nascidos terão peso entre 2.800 kg e 3.400 kg.
Determine a faixa de pesos dos recém-nascidos do Exemplo 1 com uma margem de confiança de 99,7%.
O erro de amostragem com 99,7% de confiança é 3 σ / √n, que para o nosso exemplo é E = 3 * 0,15 kg = 0,45 kg. A partir daqui infere-se que 99,7% dos recém-nascidos terão peso entre 2.650 kg e 3.550 kg.
Determine o fator Zγ para um nível de confiabilidade de 75%. Determine a margem de erro de amostragem com este nível de confiabilidade para o caso apresentado no exemplo 1.
O nível de confiança isso é γ = 75% = 0,75 que está relacionado com o nível de significância α através do relacionamento γ= (1 - α), de modo que o nível de significância seja α = 1 - 0,75 = 0,25.
Isso significa que a probabilidade normal cumulativa entre -∞ e Zγ isso é:
P (Z ≤ Zγ ) = 1 - 0,125 = 0,875
O que corresponde a um valor Zγ 1.1503, conforme mostrado na Figura 3.
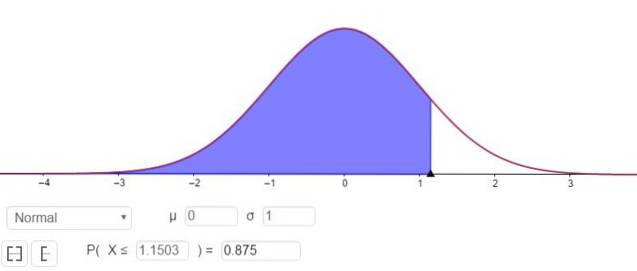
Ou seja, o erro de amostragem é E = Zγ⋅(σ / √n)= 1,15⋅(σ / √n).
Quando aplicado aos dados do exemplo 1, dá um erro de:
E = 1,15 * 0,15 kg = 0,17 kg
Com um nível de confiança de 75%.
Qual é o nível de confiança se Zα / 2 = 2,4 ?
P (Z ≤ Zα / 2 ) = 1 - α / 2
P (Z ≤ 2,4) = 1 - α / 2 = 0,9918 → α / 2 = 1 - 0,9918 = 0,0082 → α = 0,0164
O nível de significância é:
α = 0,0164 = 1,64%
E, finalmente, o nível de confiança permanece:
1- α = 1 - 0,0164 = 100% - 1,64% = 98,36%



Ainda sem comentários