O homocedasticidade em um modelo estatístico preditivo ocorre se em todos os grupos de dados de uma ou mais observações, a variância do modelo em relação às variáveis explicativas (ou independentes) permanece constante.
Um modelo de regressão pode ser homocedástico ou não, caso em que falamos de heterocedasticidade.
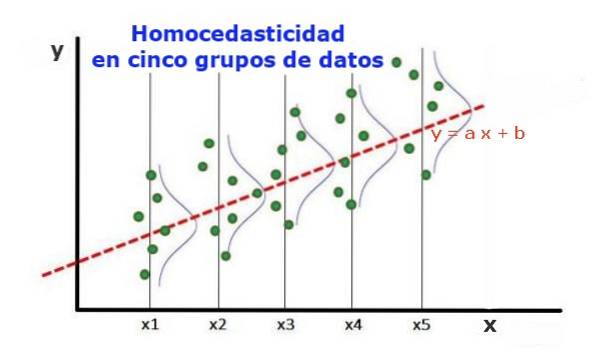
Um modelo de regressão estatística de várias variáveis independentes é denominado homocedástico, apenas se a variância do erro da variável prevista (ou o desvio padrão da variável dependente) permanecer uniforme para diferentes grupos de valores das variáveis explicativas ou independentes.
Nos cinco grupos de dados da Figura 1, foi calculada a variância em cada grupo, em relação ao valor estimado pela regressão, resultando em ser o mesmo em cada grupo. É ainda assumido que os dados seguem a distribuição normal.
No nível gráfico, significa que os pontos estão igualmente espalhados ou espalhados em torno do valor predito pelo ajuste de regressão, e que o modelo de regressão tem o mesmo erro e validade para o intervalo da variável explicativa..
Índice do artigo
Para ilustrar a importância da homocedasticidade nas estatísticas preditivas, é necessário contrastar com o fenômeno oposto, a heterocedasticidade.
No caso da figura 1, em que há homocedasticidade, é verdade que:
Var ((y1-Y1); X1) ≈ Var ((y2-Y2); X2) ≈… Var ((y4-Y4); X4)
Onde Var ((yi-Yi); Xi) representa a variância, o par (xi, yi) representa os dados do grupo i, enquanto Yi é o valor previsto pela regressão para o valor médio Xi do grupo. A variação dos n dados do grupo i é calculada da seguinte forma:
Var ((yi-Yi); Xi) = ∑j (yij - Yi) ^ 2 / n
Ao contrário, quando ocorre heterocedasticidade, o modelo de regressão pode não ser válido para toda a região em que foi calculado. A Figura 2 mostra um exemplo desta situação.
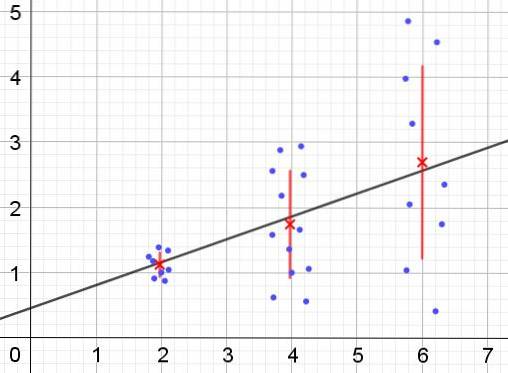
A Figura 2 representa três grupos de dados e o ajuste do conjunto usando uma regressão linear. Deve-se notar que os dados do segundo e terceiro grupos são mais dispersos do que no primeiro grupo. O gráfico da figura 2 também mostra o valor médio de cada grupo e sua barra de erro ± σ, com o desvio padrão σ de cada grupo de dados. Deve ser lembrado que o desvio padrão σ é a raiz quadrada da variância.
Es claro que en el caso de la heterocedasticidad, el error de la estimación por regresión es cambiante en el rango de valores de la variable explicativa o independiente, y en los intervalos donde este error es muy grande, la predicción por regresión es poco confiable o não aplicável.
Em um modelo de regressão, os erros ou resíduos (e -Y) devem ser distribuídos com igual variância (σ ^ 2) ao longo do intervalo de valores da variável independente. É por esta razão que um bom modelo de regressão (linear ou não linear) deve passar no teste de homocedasticidade..
Os pontos mostrados na figura 3 correspondem aos dados de um estudo que busca uma relação entre os preços (em dólares) das casas em função do tamanho ou área em metros quadrados.
O primeiro modelo a ser testado é o de uma regressão linear. Em primeiro lugar, nota-se que o coeficiente de determinação R ^ 2 do ajuste é bastante alto (91%), portanto pode-se pensar que o ajuste é satisfatório..
No entanto, duas regiões podem ser claramente distinguidas do gráfico de ajuste. Um deles, o da direita encerrado em oval, cumpre homocedasticidade, enquanto a região da esquerda não apresenta homocedasticidade..
Isso significa que a previsão do modelo de regressão é adequada e confiável no intervalo entre 1800 m ^ 2 a 4800 m ^ 2, mas muito inadequada fora desta região. Na zona heterocedástica, além de o erro ser muito grande, os dados parecem seguir uma tendência diferente da proposta pelo modelo de regressão linear..
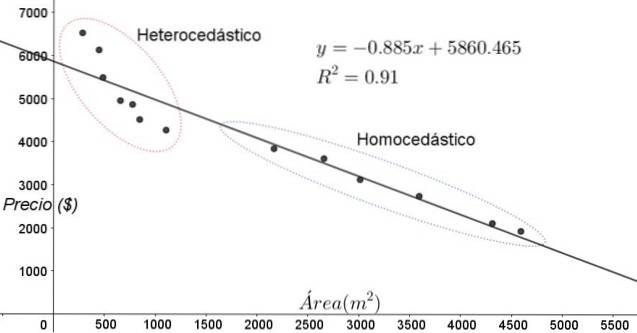
O gráfico de dispersão dos dados é o teste mais simples e visual de sua homocedasticidade, porém nas ocasiões em que não é tão evidente como no exemplo mostrado na figura 3, é necessário recorrer a gráficos com variáveis auxiliares..
Para separar as áreas onde a homocedasticidade é cumprida e onde não é, são introduzidas as variáveis padronizadas ZRes e ZPred:
ZRes = Abs (y - Y) / σ
ZPred = Y / σ
Ressalta-se que essas variáveis dependem do modelo de regressão aplicado, uma vez que Y é o valor da previsão da regressão. Abaixo está o gráfico de dispersão ZRes vs ZPred para o mesmo exemplo:
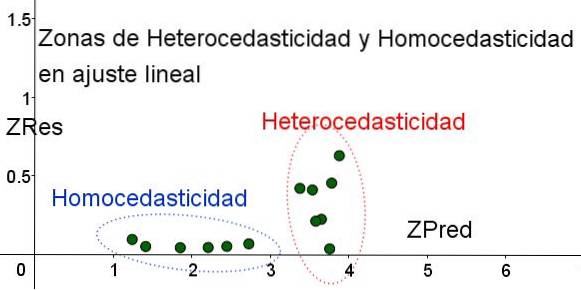
No gráfico da Figura 4 com as variáveis padronizadas, a área onde o erro residual é pequeno e uniforme é claramente separada da área onde não é. Na primeira zona, a homocedasticidade é atendida, enquanto na região onde o erro residual é altamente variável e grande, a heterocedasticidade é atendida..
O ajuste de regressão é aplicado ao mesmo grupo de dados da figura 3, neste caso o ajuste é não linear, pois o modelo utilizado envolve uma função potencial. O resultado é mostrado na figura a seguir:
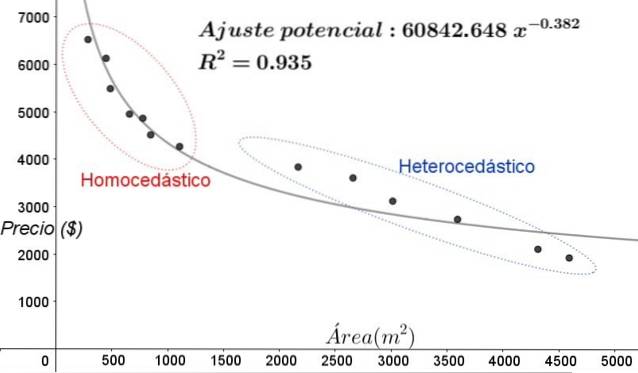
No gráfico da Figura 5, as zonas homocedástica e heterocedástica devem ser claramente observadas. Deve-se notar também que essas zonas foram trocadas em relação àquelas que foram formadas no modelo de ajuste linear.
No gráfico da figura 5 fica evidente que mesmo quando existe um coeficiente de determinação do ajuste bastante elevado (93,5%), o modelo não é adequado para todo o intervalo da variável explicativa, visto que os dados para valores maiores que 2.000 m ^ 2 apresentam heterocedasticidade.
Um dos testes não gráficos mais utilizados para verificar se a homocedasticidade é cumprida ou não é o Teste Breusch-Pagan.
Nem todos os detalhes deste teste serão dados neste artigo, mas suas características fundamentais e as etapas do mesmo são descritas em linhas gerais:
A maioria dos pacotes de software estatístico como: SPSS, MiniTab, R, Python Pandas, SAS, StatGraphic e vários outros incorporam o teste de homocedasticidade de Breusch-Pagan. Outro teste para verificar a uniformidade de variância do Teste de Levene.


Ainda sem comentários