O terceira forma normal (bancos de dados) é uma técnica de desenho de banco de dados relacional, onde as diferentes tabelas que o compõem não apenas cumprem a segunda forma normal, mas todos os seus atributos ou campos dependem diretamente da chave primária.
Ao projetar um banco de dados, o objetivo principal é criar uma representação precisa dos dados, as relações entre eles e as restrições de dados relevantes..
Para atingir esse objetivo, algumas técnicas de design de banco de dados podem ser utilizadas, entre as quais está a normalização.
É um processo de organização dos dados em um banco de dados para evitar redundâncias e possíveis anomalias na inserção, atualização ou eliminação dos dados, gerando um desenho simples e estável do modelo conceitual..
Ele começa examinando o relacionamento funcional ou dependência entre os atributos. Descrevem algumas propriedades dos dados ou a relação entre eles.
Índice do artigo
A normalização usa uma série de testes, chamados de formulários normais, para ajudar a identificar o agrupamento ideal desses atributos e, por fim, estabelecer o conjunto apropriado de relacionamentos que oferecem suporte aos requisitos de dados de uma empresa.
Ou seja, a técnica de normalização é construída em torno do conceito de forma normal, que define um sistema de restrições. Se uma relação atende às restrições de uma forma normal particular, a relação é considerada nessa forma normal.
Diz-se que uma tabela está em 1FN se todos os atributos ou campos dentro dela contiverem apenas valores únicos. Ou seja, cada valor para cada atributo deve ser indivisível.
Por definição, um banco de dados relacional sempre será normalizado para a primeira forma normal, porque os valores dos atributos são sempre atômicos. Todos os relacionamentos em um banco de dados estão em 1FN.
No entanto, simplesmente deixar o banco de dados assim estimula uma série de problemas, como redundância e possíveis falhas de atualização. Formas normais superiores foram desenvolvidas para corrigir esses problemas..
Lida com a eliminação de dependências circulares de uma tabela. Diz-se que uma relação está em 2FN se estiver em 1FN e também cada campo ou atributo não chave depende inteiramente da chave primária, ou mais especificamente, garante que a tabela tem um único propósito.
Um atributo não chave é qualquer atributo que não faz parte da chave primária de um relacionamento.
Ele lida com a remoção de dependências transitivas de uma tabela. Ou seja, remova os atributos não-chave que não dependem da chave primária, mas de outro atributo.
Uma dependência transitiva é um tipo de dependência funcional em que o valor de um atributo ou campo não chave é determinado pelo valor de outro campo que também não é chave..
Procure por valores repetidos em atributos não-chave para garantir que esses atributos não-chave não dependam de nada além da chave primária.
Os atributos são considerados mutuamente independentes se nenhum deles for funcionalmente dependente de uma combinação de outros. Essa independência mútua garante que os atributos possam ser atualizados individualmente, sem o perigo de afetar outro atributo..
Portanto, para que um relacionamento com o banco de dados esteja na terceira forma normal, ele deve estar de acordo com:
- Todos os requisitos de 2FN.
- Se houver atributos que não estejam relacionados à chave primária, eles devem ser removidos e colocados em uma tabela separada, relacionando ambas as tabelas por meio de uma chave estrangeira. Ou seja, não deve haver dependências transitivas.
Seja a tabela STUDENT, cuja chave primária é a identificação do aluno (STUDENT_ID) e é composta pelos seguintes atributos: STUDENT_NAME, STREET, CITY e POST_CODE, cumprindo as condições para ser 2FN.
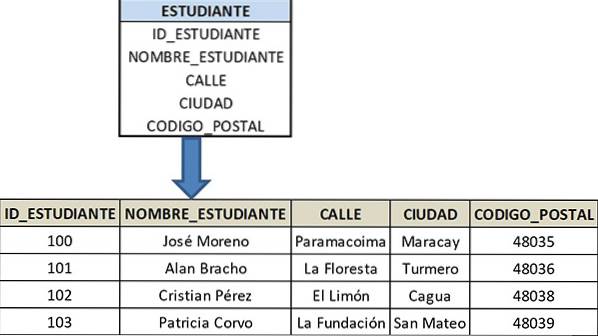
Neste caso, STREET e CITY não têm uma relação direta com a chave primária STUDENT_ID, uma vez que não estão diretamente relacionadas com o aluno, mas são totalmente dependentes do código postal.
Como o aluno está localizado no local determinado pelo CODE_POSTAL, RUA e CIDADE estão relacionados com este atributo. Devido a este segundo grau de dependência, não é necessário armazenar esses atributos na tabela ALUNO.
Suponha que existam vários alunos localizados no mesmo CEP, com a tabela ALUNO tendo uma imensa quantidade de registros, e seja necessário alterar o nome da rua ou cidade, então essa rua ou cidade deve ser encontrada e atualizada no mesa inteira. STUDENT.
Por exemplo, se for necessário mudar a rua "El Limón" para "El Limón II", você terá que procurar por "El Limón" em toda a tabela ALUNOS e depois atualizá-la para "El Limón II".
A pesquisa em uma tabela enorme e a atualização de um ou vários registros levará muito tempo e, portanto, afetará o desempenho do banco de dados.
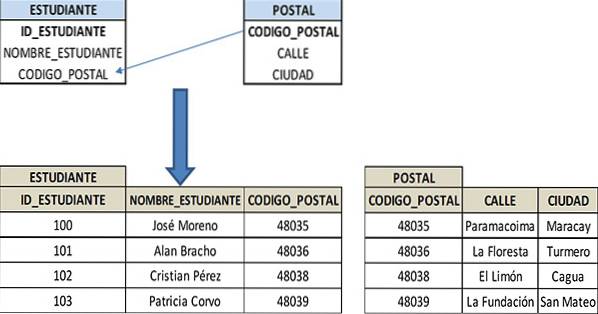
Em vez disso, esses detalhes podem ser mantidos em uma tabela separada (POSTCARD) que está relacionada à tabela STUDENT usando o atributo POST_CODE.
A tabela POST terá comparativamente menos registros e essa tabela POST precisará ser atualizada apenas uma vez. Isso será refletido automaticamente na tabela STUDENT, simplificando o banco de dados e as consultas. Portanto, as tabelas estarão em 3FN:
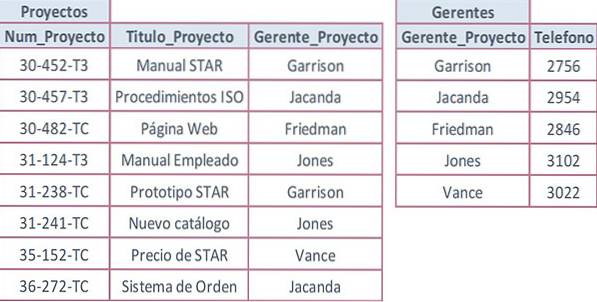
Deixe a seguinte tabela ser usada com o campo Project_Num como chave primária e com valores repetidos em atributos que não são chaves.
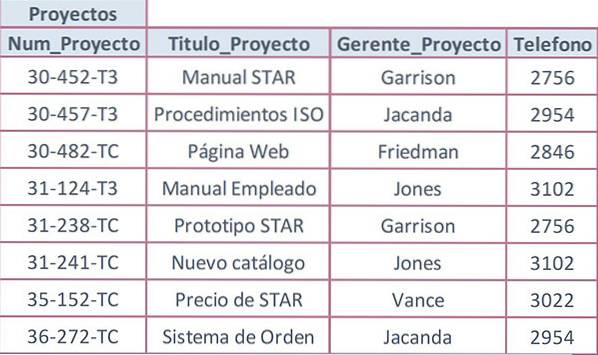
O valor Telephone é repetido sempre que o nome de um gerente é repetido. Isso ocorre porque o número de telefone só tem uma dependência de segundo grau do número do projeto. Realmente depende primeiro do gerente, e este por sua vez depende do número do projeto, o que torna uma dependência transitiva.
O atributo Project_Manager não pode ser uma chave possível na tabela Projetos porque o mesmo gerente gerencia mais de um projeto. A solução para isso é remover o atributo com os dados repetidos (telefone), criando uma tabela separada.
Os atributos correspondentes devem ser agrupados, criando uma nova tabela para salvá-los. Os dados são inseridos e verifica-se que os valores repetidos não fazem parte da chave primária. A chave primária é definida para cada tabela e as chaves estrangeiras são adicionadas se necessário.
Para cumprir a terceira forma normal, uma nova tabela (Gestores) é criada para solucionar o problema. Ambas as tabelas estão relacionadas por meio do campo Project_Manager:



Ainda sem comentários